10 Painful ways enterprise AI Assistants frustrate employees



Enterprise AI assistants promise faster resolutions, fewer tickets, and happier employees. That's the rosy picture they paint. But when they operate without the full picture, they end up creating more work, more risk, and more frustration.
The problem isn't that these assistants aren't built well. It's just that they're reasoning over incomplete, outdated, or disconnected data which doesn't give them enough context of what end-users truly want.
Without this context—a live, unified view of user identity, assets, support history, policies, and other key signals—AI assistants act in isolation. They can't tell who's asking what, the steps they've already taken, or what instructions users need to follow next.
In this article, we go over a few scenarios where our hero, the enterprise AI assistant, fails from an end-user's perspective and how a universal context layer can change the outcome.
1. The Identity Crisis: "Do you even know who I am?"
The culprit: Identity and role context missing
"I'm a visitor to the SF office. Why would I ask for help if I knew the access codes already?"
"The bot keeps asking me which team I belong to."
Breakdowns like this happen when the AI assistant can't see your end-user's role, department, employment type, location, manager, tenure, calendar blocks, or group memberships in real time.
That information usually sits in HRIS platforms like Workday and identity systems like Okta or Azure AD, or corporate directories. But it's often siloed, updated at different cadences, and formatted inconsistently. Without a comprehensive identity graph, the AI can't decide what you're allowed to do, or which workflows apply to you.
The ideal counterpart assistant acts differently. If you ask for a new laptop, it checks your eligibility in HRIS, applies replacement policies, and presents the right catalog options, all in one response with clear CTAs.
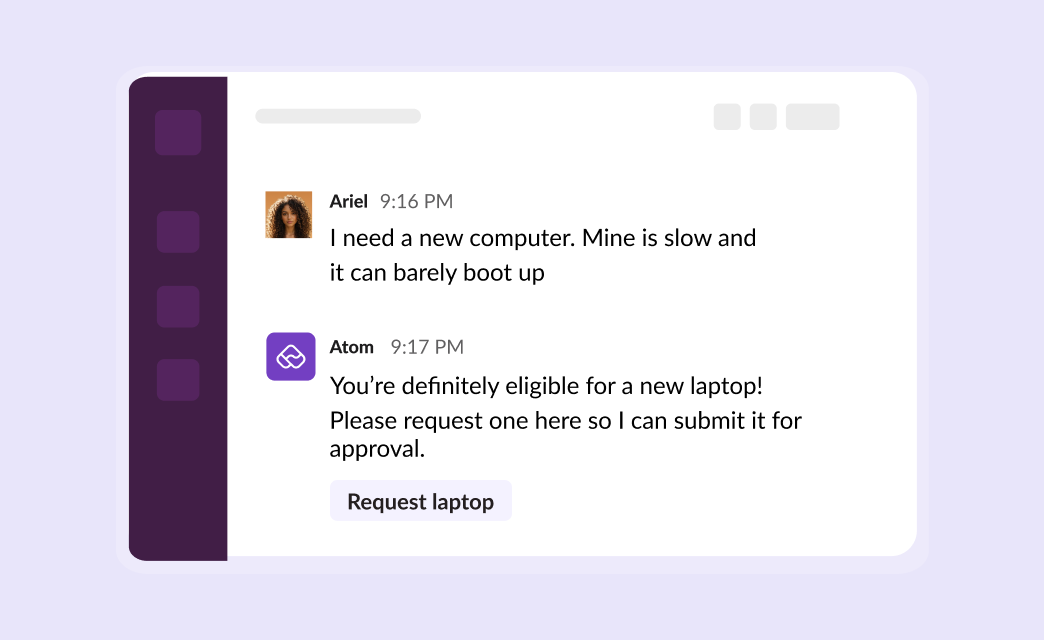
2. Wrong device, wrong advice: "It's not my laptop."
The culprit: Asset context missing
"It told me to update my old laptop… the one I returned months ago."
Without a single view of device ownership, OS version, installed software, and usage status, the assistant often acts on outdated or incorrect asset data. This information is scattered across MDM tools (Intune, Jamf), CMDB records, and software inventory systems. AI assistants struggle because these systems rarely share live, user-linked data. So they end up fixing the wrong device or suggest incompatible software.
But if all that asset context is brought in, both from an organization's perspective and from the asset's external vendor sources, it simplifies end-user device troubleshooting by several notches.
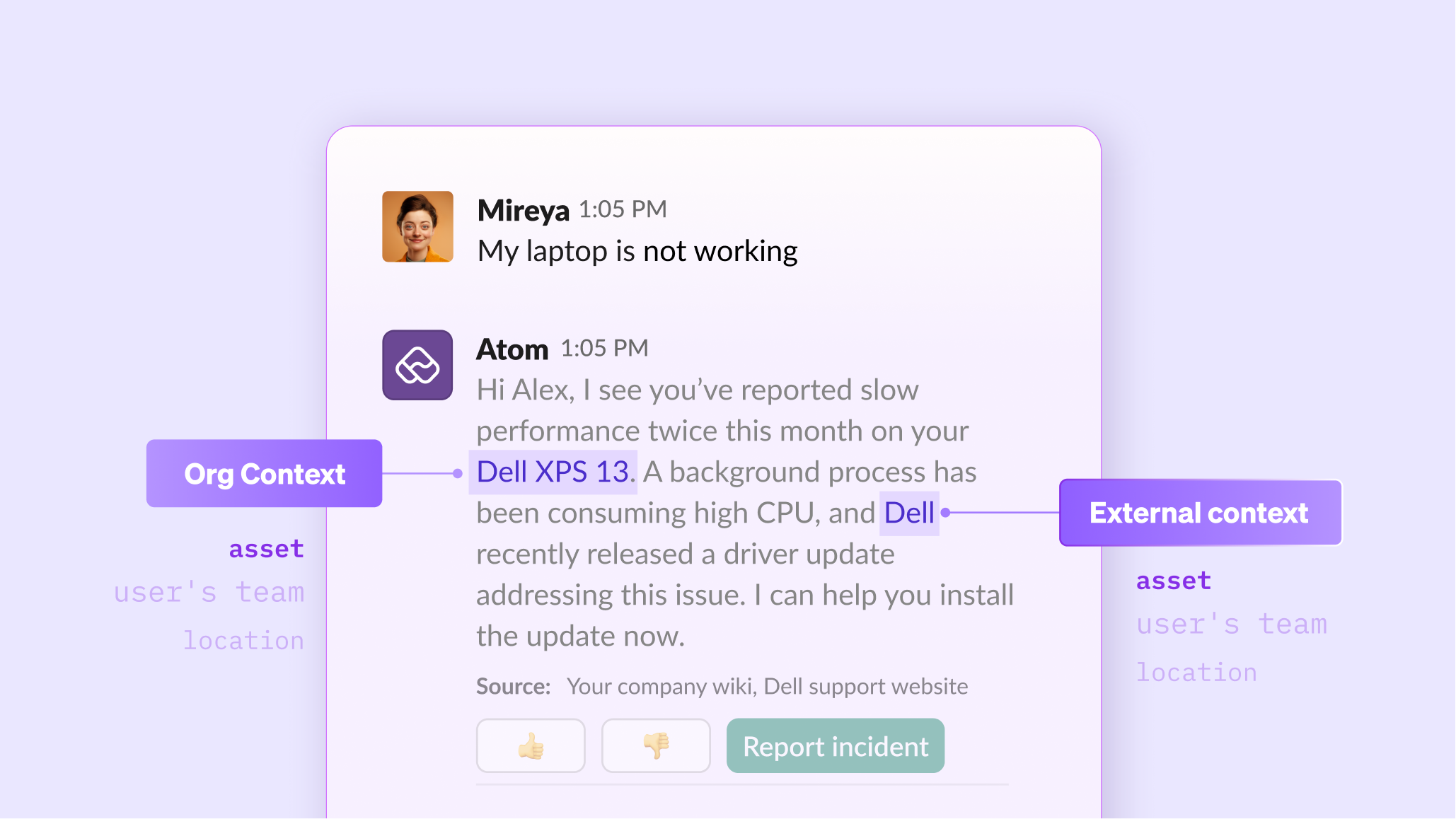
3. The Deja vu scene: "We've been over this already!"
The culprit: Support interactions and history missing
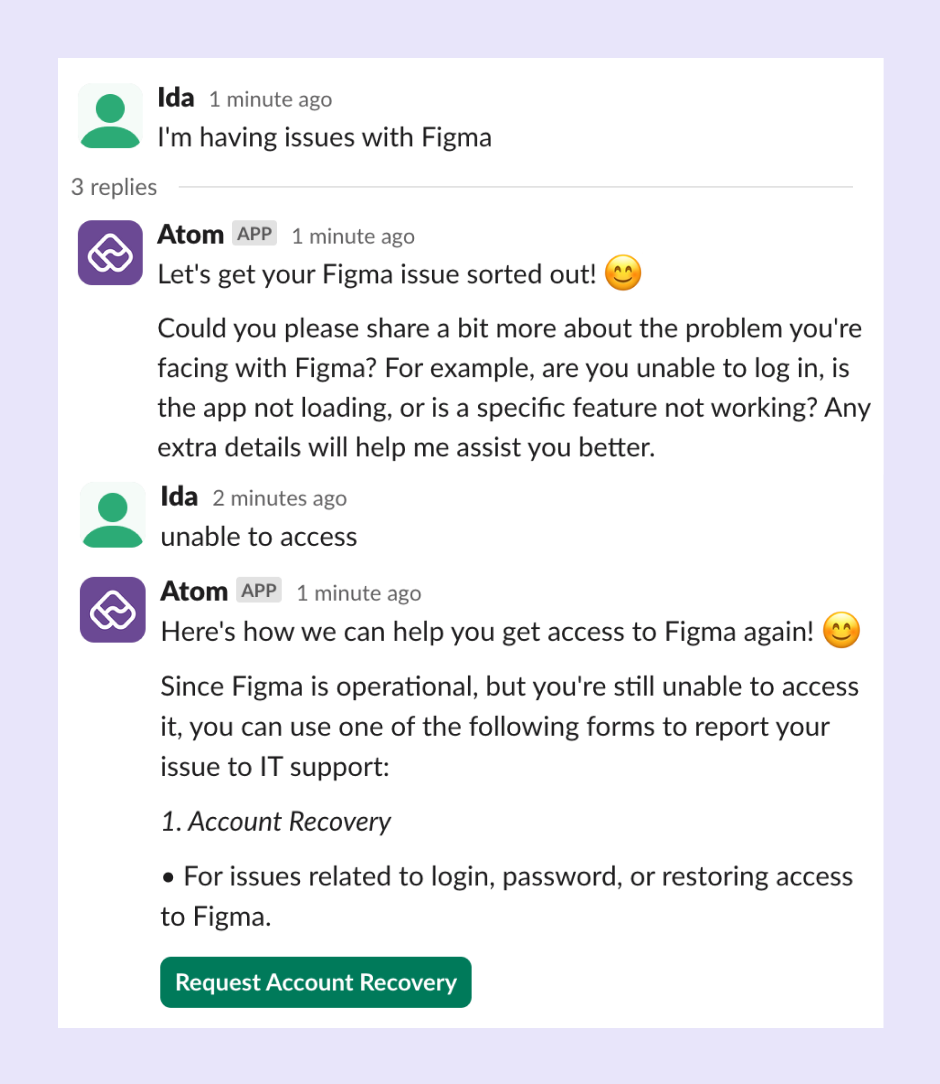
"It keeps sending me the same troubleshooting steps I tried yesterday."
Ticket histories, escalation records, and past troubleshooting attempts live in ITSM platforms, chat logs, and email archives. These systems don't naturally form a "conversation memory," so AI assistants treat every interaction as new. Without context, they repeat themselves and frustrate users.
An intelligent assistant, like Atomicwork's Universal Agent, can understand the steps previously taken by the user and suggest next-best actions that aren't repetitive.
4. Rules? What rules?: "That's not how we do things here."
The culprit: Missing context on policies and SLAs
"It approved my hardware request, but finance later rejected it."
Approval chains, SLAs, change windows, and catalog rules often live in ITSM workflows, governance tools, and static policy docs.
AI assistants stumble because these rules aren't always structured, accessible, or consistent across systems, making it hard for them to reason if it is this allowed before acting.
5. The Momentum killer: "Why can't I raise this issue on Slack?"
The culprit: No or low channel coverage.
"Why do I need to switch to the portal? Can't you just handle it on Slack?"
AI assistants often frustrate users by limiting where and how they can interact. If an employee starts a request in Slack, Teams, or email, they expect the request to be handled right there, without breaking the momentum of their work.
But most AI assistants live inside a portal, or only work in chat, or force users to switch to email or portal after answering a few initial queries. Each system logs activity differently, making it hard for AI to recognize that the same user is making the same request in a different place. Without this, the user experience feels fragmented: one channel gives you knowledge, another gives you forms, another just tells you to "go somewhere else."
At Atomicwork, we launched universal agent earlier this year just to solve for this. Employees should be able to raise and resolve issues on channels of their choice, whether it's their browser, Slack, Teams, or email.
Atom has a universal context layer so that it doesn't matter where a user starts in their mode or channel of choice, the context follows them across channels.
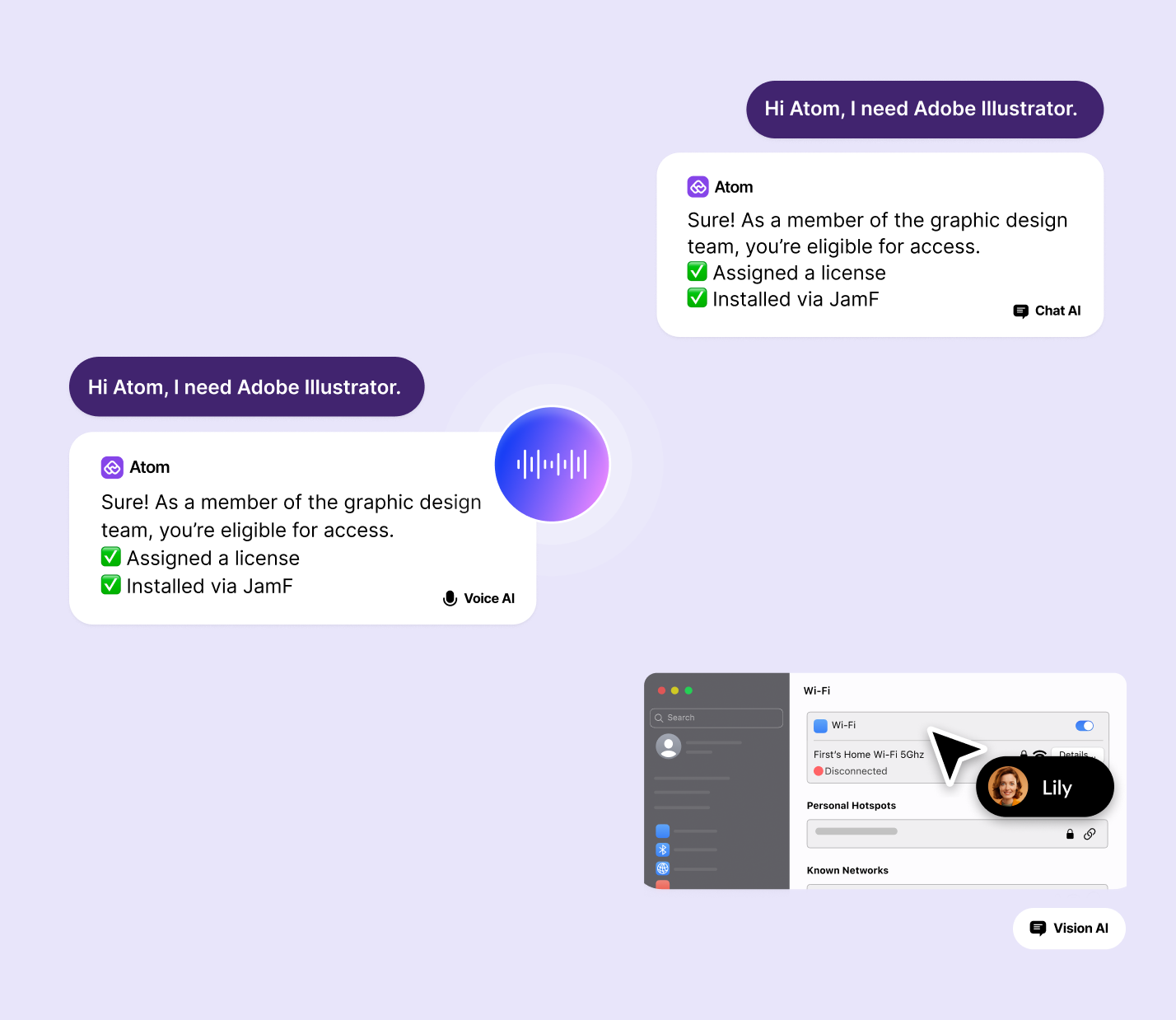
6. The over communicator: "You just sent that to the whole company."
The culprit: Security and access restrictions information missing.
Sensitive information like your employees payslips should be allowed to be accessed or pulled up only by that particular employee, their manager and the HR. Not the entire company.
Data classification, geo-residency rules, and PII restrictions live in DLP systems, compliance platforms, and security policies. AI assistants without hooks into these systems and the ability to interpret their rules often overshare. They should be configured in such a way to share specific information to specific people based on the roles and corresponding access.
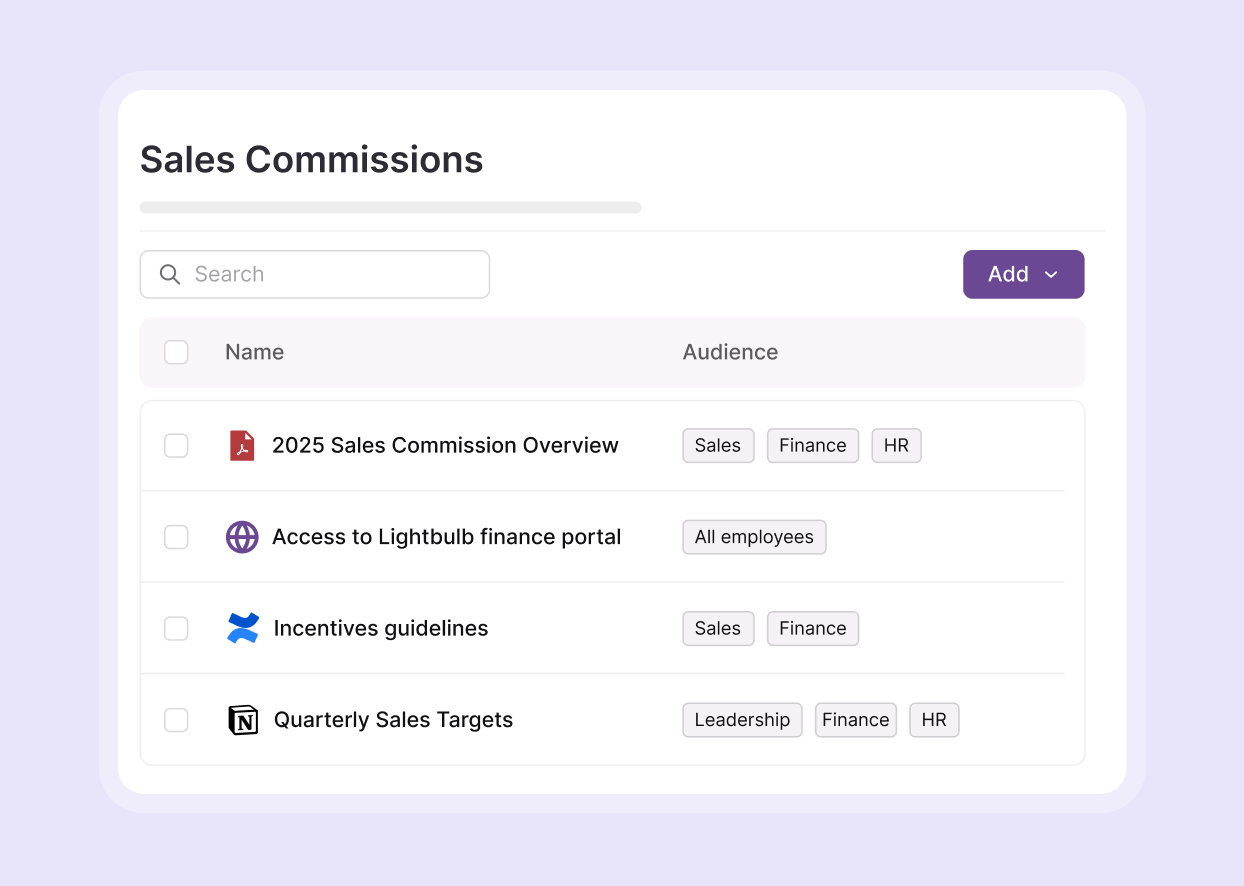
7. Stuck in a single lane: "Why give me this and nothing else?"
The culprit: Stops with generic knowledge help
"It gave me a link to the help doc but didn't let me fix the issue right there."
AI assistants usually default to linear thinking: they treat "knowledge" and "action" as separate lanes. If you ask about a login problem, they might hand you a static article or just a form, but rarely both. The information lives in different systems: knowledge bases for articles, service catalogs for request forms, and ITSM workflows for actual fulfillment. Because these sources aren't connected, the AI can't reason across them to create one seamless, actionable response.
This forces users into unnecessary back-and-forth, increasing time-to-resolution and lowering satisfaction.
Atom blends knowledge and request catalog into unified answers. If you ask for a new laptop, it pulls in the replacement policy from the KB and the correct catalog item in one response, explaining the process and giving you direct CTAs to request a device.
8. Severe trust issues: "How do I know you're right?"
The culprit: Validation sources and reasoning trails missing
"You're giving me an answer… but how do I know it's correct?"
Even when AI assistants sound confident, they rarely explain why they've given a certain answer. They might pull content from multiple sources—knowledge bases, service catalogs, or past tickets—but without surfacing the reasoning, users are left guessing about its accuracy or how updated the information is. The underlying challenge is that enterprise data lives in many systems, each with its own reliability level, and AI models don't naturally expose their decision path.
This lack of transparency erodes trust. When employees can't see the "why" behind an answer, they're more likely to double-check with a human that slow down resolution and reducing AI adoption.
Every reply by Atom is backed by a transparent reasoning trails and sources. It shows which knowledge articles, catalog items, and fallback logic were evaluated, and explains how they were combined into the final recommendation. That makes responses not only actionable, but also trustworthy and traceable.

9. The Cliffhangers: "Wait. That's a half-baked answer."
The culprit: Not every common work app is integrated with the assistant.
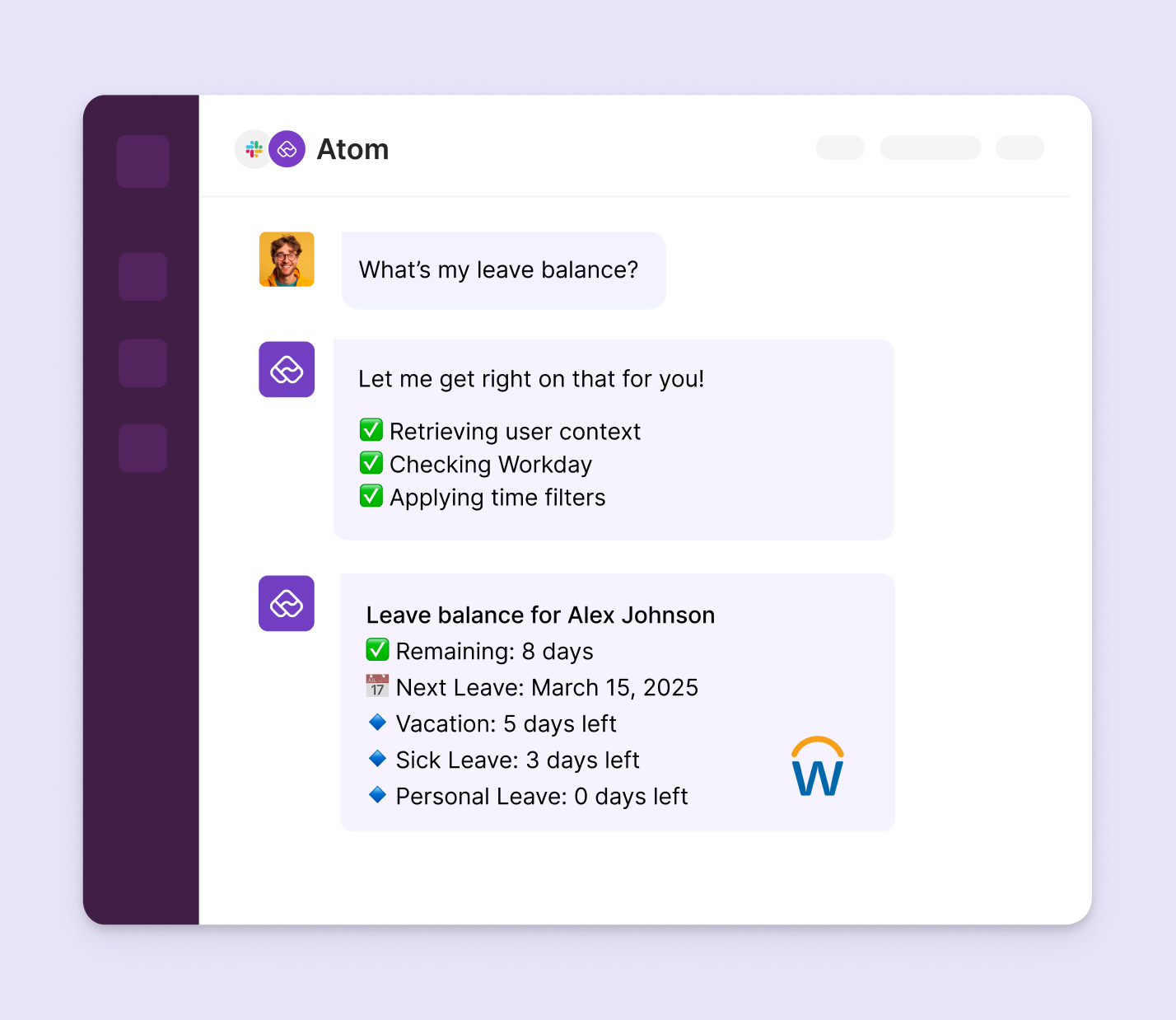
Picture this.
An employee asks an AI assistant their vacation leave balance.
The assistant pulls up the generic HR leave policy, explains how leave balances are calculated, links to an FAQ document and then...stops.
Crickets.
The user is left guessing and clicking around in another app to find what they were originally looking for.
The most frustrating AI answers aren't the wrong ones but the incomplete ones.
When your org's AI assistant is integrated the right apps, it intelligent understands the query, reasons across both knowledge and transactional systems, taps into the right app—the HRMS in this case—and pulls up a relevant and complete answer in one go, within one platform.
10. Hierarchy hurdles: "My boss left months ago."
The culprit: Org graph and relationship context missing
Sending your request to a manager who has left the company for good or to the wrong regional team, shows that the AI assistant lacks context into org structures and updates. Manager relationships, backup assignments, and team routing rules sit in HRIS, IAM, and vendor records but these often lag reality. Without up-to-date routing, AI sends requests to the wrong person or team, stalling progress.
Ideally, intelligent assistants need to use a live org graph that updates automatically, so if your manager is out, it routes approvals to the designated backup without you needing to explain.
From confidently wrong to reliably right
These failures don't happen because the AI assistant is poorly designed, they happen because it's missing the full context it needs to make the right call.
A universal context layer solves this by continuously unifying identity, assets, support history, policies, knowledge, and other real-time signals from their disparate sources. That's what enables our Universal AI Agent Atom to handle bundled requests, carry context across conversations, blend knowledge and action, and always suggest the next right step.
The result? Faster resolutions, fewer mistakes, stronger compliance—and a lot fewer "Do you even know who I am?" moments.


You may also like...



