Why service management processes fail without Context: 8 breaking points


IT service teams, in all goodwill, set up detailed ITSM processes like incident, problem, change, and request management to make service delivery faster, secure, and more predictable.
However, in practice, fragmented tools and disconnected data make these processes harder to execute. Instead of efficiency, teams face delays, rework, and a whole lot of blind spots, especially as businesses scale.
Enterprises have tried implementing a configuration management database (CMDB) to solve for the lack of visibility into their IT infra and device dependencies. On ground, though, even with detailed configuration items (CIs) and exhaustive CMDBs, the data rarely integrates into service management processes—rendering CIs and their relationships ineffective.
Service teams and AI agents need unified access to data about your users, assets, applications used, support interactions, organizational policies, SLAs, and workflow rules to operate seamlessly and deliver proactive, smarter, and faster IT support.
Allow us to explain how knowledge gaps caused by missing context shows up across your IT org, impacting service delivery.
1. Incidents pile up with delayed resolution times
When complete context is missing, every incident feels repetitive and time consuming—both when AI agents and support teams troubleshoot.
When an employee reports a VPN failure, AI agents may suggest generic fixes like restarting the laptop or reinstall the VPN client. When the problem persists, the AI agent will then give up pass it on to a human agent—frustrating and delaying user resolutions.
With context, the response of the AI agents helping the employee looks very different.
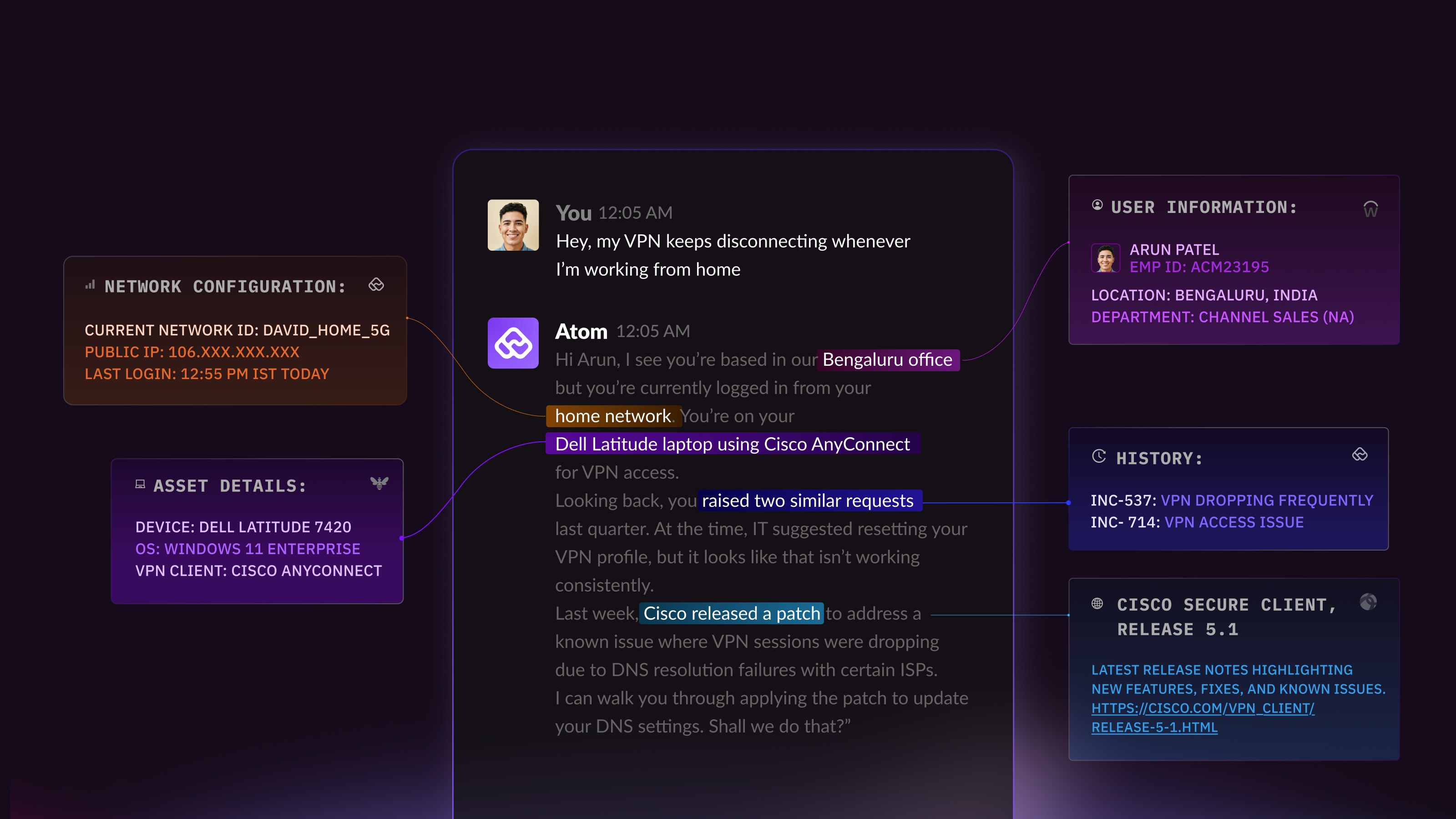
The AI agent can instantly:
- Check device health from the MDM to see if the VPN client or OS is out of date
- Pull identity data from Okta or Azure AD to flag if the user’s certificate was revoked during a recent laptop replacement
- Look across other incidents in a specific time frame to see if others in the same location are reporting the same issue that’ll hint a gateway outage or firewall block
- Cross-reference VPN logs and historical incidents to suggest the most likely root cause and the fix that worked before
- Check public, trusted sources—like Cloudflare or Checkpoint—to find out if there’s an outage on their end
As you can see, context allows AI agents to narrow down the root cause intelligently that enables it to better assist employees or handoff the issue to a human agent with deep context.
2. Changes that inadvertently introduce risk
When creating or approving changes, IT teams often spend a lot of time trying to predict the impact and possible disruptions; only to discover a server crash or tickets piling up because an app went down. So, when does impact analysis ever feel like it’s enough?
The problem usually isn’t a lack of process, but the lack of visibility into a change’s actual impact.
Take a Windows OS update, for example.
If AI can mine up-to-date, real-time information, it can help IT teams quickly :
- Identify the scope of impacted assets
- Find application compatibility after rollout
- Spot which teams will be affected and predict user disruption
- Understand past incidents tied to similar rollouts
- Notify users before the change is implemented
With this context of asset dependencies, policies, and SLAs upfront, change planning can stop being guesswork.
3. Problem records persist
Support teams often find themselves troubleshooting the same issues reactively, racing against the clock without addressing the root cause. This is because tickets solved in isolation hide patterns.
Take a recurring Wi-Fi issue as an example. Dozens of tickets may come in a week that the VPN connection keeps disconnecting. Agents may treat each one as a one-off issue, suggesting resets, adapter updates, or moving closer to the router.
But the tickets keep coming because the problem wasn’t fixed. What your team may not have visibility into is that all those incidents trace back to an outdated firmware across a group of access points—which could be the single root cause.
Without correlation across incidents, asset logs, vendor patch updates, or change records, teams are stuck treating symptoms. Context makes trends visible so IT can eliminate the root cause instead of firefighting forever.
4. Service requests get passed around endlessly
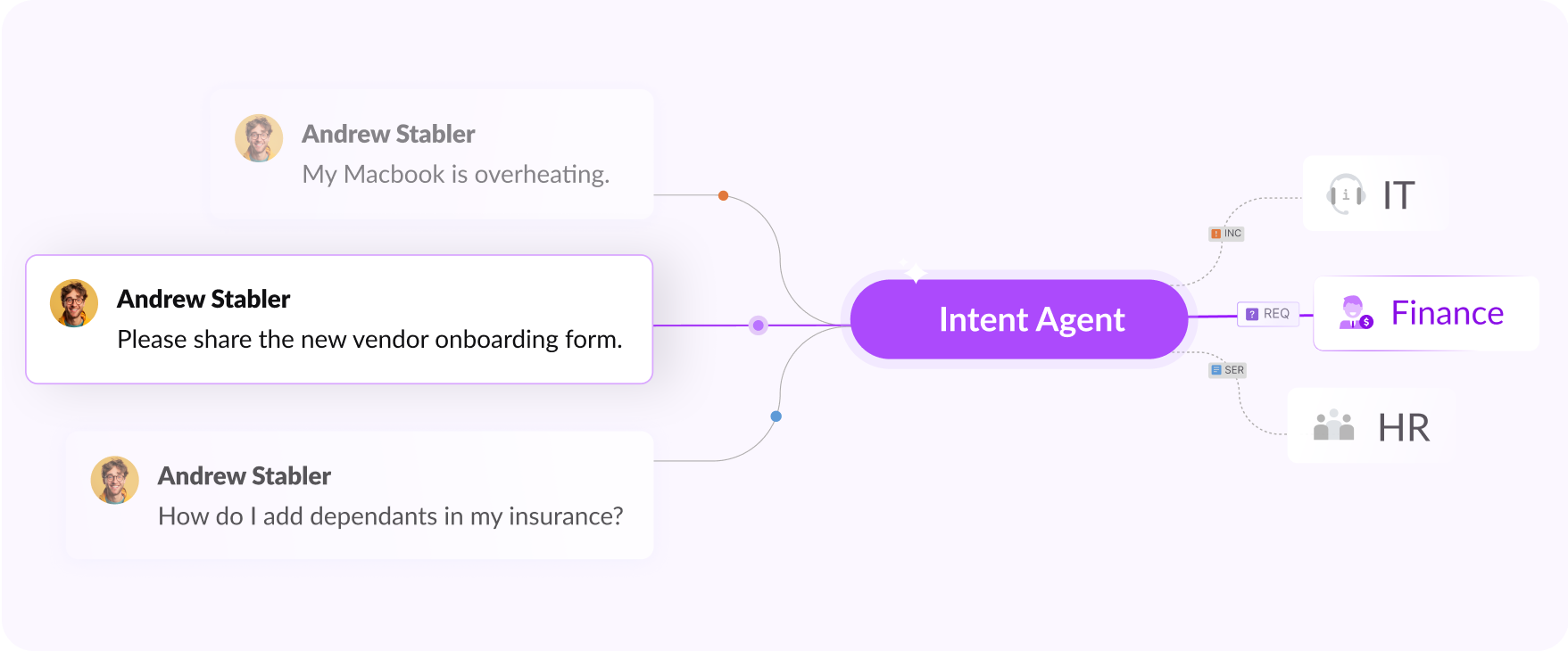
Without context being built into your routing logic, requests may get routed to the wrong team and cause delayed responses. A payroll question could land in IT, be passed on to HR, and finally may reach the Finance team after several hours. Employees see the ping-pong and their trust on IT teams erode.
AI-powered context learns and adapts based on your organization’s tribal knowledge of queries routed and resolved in the past by different team. This smart routing then ensures that the user intent is identified accurately right when an employee logs a request so that every query lands with the right service desk at the right time.
5. Mismatched app access requests
Improper provisioning of access is one of the biggest security risks IT faces, and it often stems from missing context.
Let’s say a junior sales executive requires edit access to specific dashboards in their organization’s HubSpot CRM.
The AI agent that’s tasked with provisioning the access,
- Checks if the user already has edit access but is unaware (from Okta/AD)
- Checks if the requestor has the necessary entitlements to make changes to the report
- Sends the request to the manager for approval, if the necessary permissions don’t exist
- Provisions access once approved
But without context linking user roles, entitlements, policies, and approval paths, both AI agents and IT teams end up in endless back-and-forth with end users, justifying access upgrades and waiting on approvals.
6. Assets go unmanaged
Asset data isn’t meant to sit idle within CMDBs. It’s what IT teams need to depend on while handling critical incidents and changes that directly involve live context from enterprise devices.
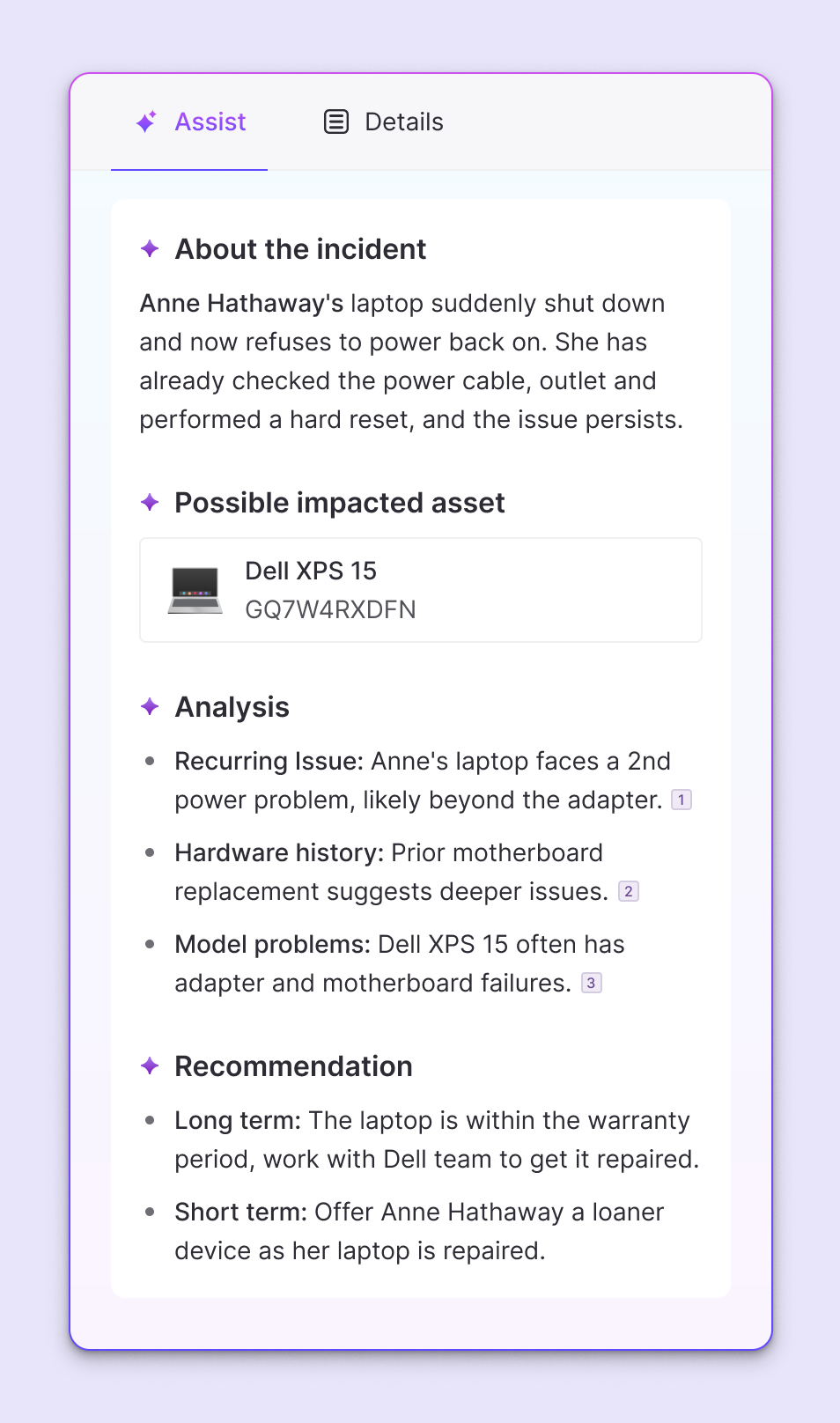
Imagine an AI agent trying to troubleshoot an end user’s laptop that’s reported to be running slow. Asset context can shape a sharp and smart agent responses by:
- Identifying the user’s device model from MDMs like Kandji or Intune
- Checking recent software installs or updates made on the device
- Flagging any known compatibility issues between an app version and the current OS version
- Reviewing background processes and memory usage in the impacted device through telemetry
With live asset context on CMDB records, device telemetry, and ownership, IT teams stop spending time in blind troubleshooting and start solving with accuracy.
7. Analytics miss the broad story
Traditional ITSM metrics like ticket volumes or MTTR may help gauge overall patterns in the request flows. However, they do not necessarily give the full picture of end user service journeys—their expectations and frustrations.
On paper, numbers for Jira or Salesforce access requests may show that they’re being closed within SLA. The AI assistant may also show strong “deflection” numbers because it points employees to the right forms.
But when you zoom out, you see a different scenario play out. Employees might have requested in Slack for Salesforce access, then logged a request in the IT portal, and when approval lags, followed up with managers on email. The overall resolution journey would’ve actually been slow, but the IT leadership doesn’t see the friction due to context-blind analytics.
With context, these conversations, tickets, and emails are clustered into a single view as complete user journeys, that’ll help IT teams pinpoint where a workflow or catalog item change is needed for frictionless employee journeys.
8. Agent burnout peaks
Behind every delayed resolution is often an agent toggling anywhere between 5 to 10 different tools just to gather enough information to act. For an access issue, they might check Active Directory for user groups, HRIS for entitlements, CMDB for device history, and ITSM for workflow eligibility.
Now, multiply this across hundreds of tickets a week, and the toll is obvious: slower resolutions, exhausted IT teams, and unhappy end users.
AI-powered context brings all that matters into one place, so agents can focus on solving and not searching for information.
From fragmented service interactions to context-driven ITSM
ITSM processes don’t fail because of flawed strategy. They fail because they function without a complete picture on user identity, application permissions, device details, or request histories.
With a universal context layer, every part of ITSM changes: incidents get closed, risks in changes are mitigated, root causes no longer lay hidden, and request fulfilment gets expedited.
With context-rich IT operations, IT teams get their time back, leaders operate with clarity, and employees get services they can trust every single time. Talk to us today if you want to run context-enriched ITSM processes!


You may also like...



